AI-Powered Site Investigation
Contamination plumes can be extremely difficult to investigate. Creating conceptual site models requires days of field work on-site to collect hydrology, chemistry, and geology data that then feeds into many hours of analysis.
As a result, site models can be expensive to develop. Their use in remediation actions and decisions by regulators is driven by an accurate understanding of how much material is beneath the surface, its concentration, if it is moving, andthe overall footprint of the affected area.
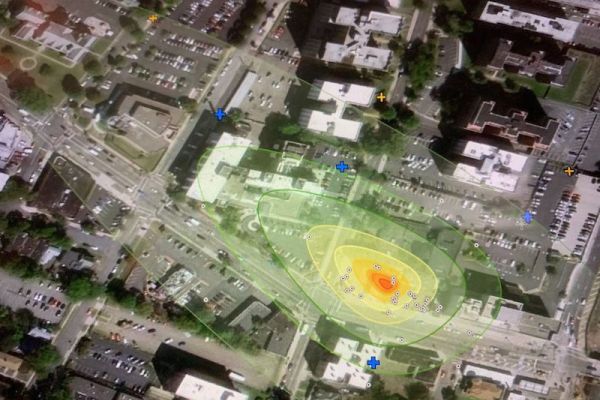
To speed this process, EnviMetric creates a forecast of the extent of contamination to soil and groundwater after a leak or spill is discovered based on a proprietary database of past plumes.
A data-driven approach to remediation
EnviMetric is a data-driven approach that compiles all of the discoveries and learning from thousands of prior LNAPL, DNAPL, and PFAS sites into a predictive model that describes the affected area - how far it stretches from the origin, how widely it is dispersed, and how deep it goes. Our machine learning approach synthesizes the millions of bits of information gained from years of site investigation and fits it to the target site.
No additional soil and groundwater sampling
The model is created without any new field work by instead leveraging information about the current site as it relates to the thousands of others in our collection.
Open and defensible evidence for planning, monitoring, and litigation
Far from being a ‘black box’, each EnviMetric model comes with a complete explanation of how the resulting model output was derived; a description of the data relationships that drive the model output; and statistical data that put the model in context with other sites with similar geography, hydrology, chemistry, and geology.